Décryptage du rapport P1 — Des courbes de rotation au lentillage faible : comment tester la réponse gravitationnelle moyenne d’EFT
Version explicative destinée au public, fondée sur « P1_RC_GGL : test de fermeture strict de la dynamique galactique et du lentillage faible (v1.1) »
Consultez le rapport d’évaluation original :
1. ChatGPT : https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini : https://gemini.google.com/share/773ec96d75a0
3. Grok : https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen : https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek : https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
6. Doubao : https://www.doubao.com/thread/w166b207d7345e46a
Note de lecture |
Il s’agit d’une « version explicative », et non d’un autre rapport scientifique. Elle s’appuie sur le rapport P1 original, conserve les figures et tableaux essentiels, et ajoute à chaque étape clé une explication publique de « ce que cela signifie ». |
Ce texte explique uniquement les conclusions obtenues par P1 dans ses jeux de données, son registre de paramètres et son protocole statistique définis : dans le test conjoint des courbes de rotation galactiques (RC) et du lentillage faible galaxie-galaxie (GGL), le modèle de réponse gravitationnelle moyenne d’EFT devance nettement la base DM_RAZOR minimale testée ici. |
Ce texte n’interprète pas P1 comme une conclusion selon laquelle « la matière noire serait renversée ». P1 n’est que la première étape de la série P : il teste un seul niveau observable d’EFT, le « socle gravitationnel moyen », et non l’ensemble de la théorie EFT. |
0 | Comprendre P1 en cinq minutes : que fait-on exactement ici ?
On peut voir P1 comme une expérience de vérification mutuelle entre sondes. Il ne s’agit pas seulement de demander si un modèle peut ajuster un jeu de données ; deux lectures gravitationnelles très différentes sont placées sur le même banc d’audit : les courbes de rotation (RC) lisent la dynamique des disques galactiques, tandis que le lentillage faible galaxie-galaxie (GGL) lit la réponse gravitationnelle projetée à plus grande échelle.
- Les RC jouent le rôle d’un « compteur de vitesse » : elles indiquent à quelle vitesse le gaz et les étoiles tournent à différents rayons dans le disque galactique.
- Le GGL joue le rôle d’une « balance » : en mesurant la légère déviation de la lumière d’arrière-plan par des galaxies d’avant-plan, il permet d’inférer la distribution moyenne de gravité ou de masse autour des galaxies à plus grande échelle.
- La question centrale de P1 est la suivante : un même modèle peut-il d’abord apprendre une régularité à partir des RC, puis la transférer au GGL tout en restant cohérent ?
La phrase centrale de P1 |
P1 élève le seuil de comparaison de « l’ajustement isolé est-il bon ? » à « peut-on fermer entre sondes ? ». Ce n’est que si le modèle se comporte bien sous la bonne correspondance et que le signal s’effondre après mélange que l’on peut dire qu’il a plus probablement saisi une structure gravitationnelle partagée entre RC et GGL. |
Tableau 0 | Les chiffres clés de P1 et leur lecture pour un public général
Indicateur | Lecture dans P1 / P1A | Comment un lecteur général peut le comprendre |
Ajustement conjoint ΔlogL_total | Dans la comparaison principale du texte, EFT vaut 1155–1337 par rapport à DM_RAZOR | Différence de score total lorsque les deux jeux de données sont combinés ; plus elle est grande, meilleure est l’explication globale. |
Force de fermeture ΔlogL_closure | Dans la comparaison principale du texte, EFT vaut 172–281, contre 127 pour DM_RAZOR | Capacité à prédire le GGL après inférence sur RC seulement ; plus elle est grande, plus le modèle est « auto-cohérent entre sondes ». |
Contrôle négatif shuffle | Après mélange RC-bin→GGL-bin, le signal de fermeture d’EFT tombe à 6–23 | Si la bonne correspondance est détruite, l’avantage doit disparaître ; plus cette disparition est nette, mieux on écarte les faux signaux. |
Test de résistance P1A multi-DM | DM 7+1 + DM_STD, avec EFT_BIN conservé comme témoin | P1A ne se limite pas au DM_RAZOR minimal ; il place plusieurs branches d’amélioration DM de faible dimension et auditables dans le même protocole de fermeture. |
1 | Pourquoi réaliser P1 : où la cosmologie à l’échelle des galaxies bloque-t-elle aujourd’hui ?
Les problèmes à l’échelle galactique restent difficiles parce que le besoin d’une « gravité ou masse supplémentaire » n’est pas seulement un phénomène de courbes de rotation. De nombreuses observations montrent un lien étroit entre la matière baryonique visible dans les galaxies et les lectures dynamiques ou de lentillage effectives. Pour les approches par matière noire, cela signifie que les halos sombres, le feedback baryonique, l’histoire de formation des galaxies et les erreurs systématiques d’observation doivent être coordonnés avec une grande finesse ; pour les approches gravitationnelles sans matière noire, cela signifie qu’un modèle ne peut pas seulement bien se comporter sur les RC : il doit aussi rester valable en lentillage faible, dans les lois d’échelle de populations et sous contrôles négatifs.
C’est précisément la motivation de P1 : il ne part pas de l’idée que « la matière noire est fausse » ou que « EFT est forcément juste ». Il soumet plutôt une proposition testable à examen : la réponse gravitationnelle moyenne d’EFT peut-elle laisser, dans la fermeture inter-sondes RC→GGL, un signal reproductible et transférable ?
Contexte de la littérature externe : pourquoi la fenêtre RC+GGL est-elle importante ? |
La relation d’accélération radiale (RAR) proposée par McGaugh, Lelli et Schombert en 2016 montre une corrélation étroite, avec une faible dispersion, entre l’accélération observée suivie par les courbes de rotation et l’accélération prédite par la matière baryonique. Cela fait du « couplage baryons–réponse gravitationnelle » une question incontournable pour les théories à l’échelle galactique. |
Brouwer et al. (2021) ont utilisé le lentillage faible KiDS-1000 pour étendre la RAR à des accélérations plus faibles et à de plus grands rayons, tout en comparant MOND, la gravité émergente de Verlinde et des modèles LambdaCDM ; ils soulignent aussi que les différences entre galaxies de type précoce et tardif, les halos gazeux et la connexion galaxie–halo restent des questions explicatives clés. |
Mistele et al. (2024) ont ensuite utilisé le lentillage faible pour inférer les courbes de vitesse circulaire de galaxies isolées ; ils rapportent qu’elles ne présentent pas de baisse nette sur plusieurs centaines de kpc, voire jusqu’à environ 1 Mpc, et qu’elles sont compatibles avec la BTFR. Cela montre que le lentillage faible devient une lecture externe importante pour tester la réponse gravitationnelle à l’échelle galactique. |
La valeur de P1 n’est donc pas d’être « le premier à discuter ensemble RC et GGL ». Elle tient au fait de les inscrire dans un protocole auditable composé d’une correspondance fixe, d’un registre de paramètres, d’une fermeture RC-only→GGL, d’un contrôle négatif par shuffle et de tests de résistance P1A avec plusieurs modèles DM.
2 | Que signifie EFT dans P1 ? Ce n’est pas Effective Field Theory
Ici, EFT désigne la Théorie des filaments d’énergie (Energy Filament Theory, EFT), et non l’Effective Field Theory courante en physique. Dans le rapport technique P1, l’usage d’EFT est très retenu : elle n’entre pas en compétition comme théorie ultime complète, mais est d’abord condensée en une paramétrisation observable, ajustable et réfutable de la « réponse gravitationnelle moyenne ».
En langage simple : P1 ne discute pas d’abord toutes les sources microscopiques d’une gravité supplémentaire et ne tente pas de prouver d’un seul coup l’ensemble d’EFT. Il pose une question plus étroite et plus exigeante : s’il existe à l’échelle galactique une certaine réponse gravitationnelle supplémentaire moyenne, peut-elle d’abord expliquer les RC, puis être transférée pour prédire le GGL ?
Quelle partie d’EFT P1 saisit-il ? |
P1 saisit le « socle gravitationnel moyen » (mean gravity floor) : une contribution moyenne statistiquement stable et transférable entre échantillons. |
P1 ne traite pas encore le « socle de bruit » (stochastic / noise floor) : c’est-à-dire les termes aléatoires, différences individuelles ou dispersions supplémentaires que pourraient produire des processus de fluctuation plus microscopiques. |
P1 ne discute pas non plus le mécanisme microscopique complet, l’abondance, les durées de vie ni les contraintes cosmologiques globales. C’est la première étape de la série P, non un verdict final. |
3 | Le programme de la série P1 : pourquoi commencer par le « socle moyen » ?
La série P peut être comprise comme le programme de recherche observationnelle d’EFT. Elle n’étale pas toutes les propositions en une seule fois ; elle isole d’abord l’élément le plus facilement testable avec des données publiques. La stratégie de P1 consiste à tester d’abord le terme moyen : si la réponse gravitationnelle moyenne ne parvient même pas à fermer RC→GGL, discuter ensuite de termes de bruit plus complexes ou de mécanismes microscopiques manquerait de point d’entrée.
Tableau 1 | Positionnement par couches de la série P
Niveau | Question posée | Place dans P1 |
P1 | La réponse gravitationnelle moyenne peut-elle fermer dans RC→GGL ? | Question principale du rapport actuel |
P1A | Si l’on renforce le côté DM, la conclusion reste-t-elle stable ? | Annexe B : test de résistance DM 7+1 + DM_STD |
Suite de la série P | Peut-on étendre le protocole à davantage de données, de sondes et de systématiques plus complexes ? | Direction des travaux ultérieurs |
Questions plus profondes | Comment le terme moyen, les termes de bruit et les mécanismes microscopiques se relient-ils ? | Hors du périmètre conclusif de P1 |
4 | Quelles sont les données ? Que nous disent respectivement RC et GGL ?
4.1 Courbes de rotation RC : le « tachymètre » du disque galactique
Les courbes de rotation enregistrent la vitesse à laquelle le gaz et les étoiles orbitent autour du centre galactique à différents rayons. Plus la rotation est rapide, plus la force centripète requise à ce rayon est forte, donc plus la gravité effective est élevée. P1 utilise la base SPARC ; après prétraitement, elle comprend 104 galaxies et 2 295 points de vitesse, répartis en 20 RC-bins.
4.2 Lentillage faible GGL : une « balance gravitationnelle » à plus grande échelle
Le lentillage faible galaxie-galaxie mesure la manière dont les galaxies d’avant-plan courbent légèrement la lumière de galaxies d’arrière-plan. Il correspond à la réponse gravitationnelle projetée à plus grande échelle, celle du halo, sans dépendre des détails de la dynamique du gaz galactique. P1 utilise les données GGL publiques de KiDS-1000 / Brouwer et al. 2021 : 4 bins de masse stellaire, 15 points radiaux par bin, soit 60 points au total, avec la covariance complète.
4.3 Correspondance fixe : pourquoi 20 RC-bins → 4 GGL-bins est-il si crucial ?
P1 relie les 20 RC-bins aux 4 GGL-bins par une règle fixe : chaque GGL-bin correspond à 5 RC-bins, avec une moyenne pondérée par le nombre de galaxies. Cette correspondance reste identique pour tous les modèles et constitue une contrainte dure pour le test de fermeture et la comparaison équitable.
Pourquoi ne peut-on pas ajuster la correspondance après coup ? |
Si l’on autorisait le choix après coup de « quels RC-bins correspondent à quels GGL-bins », un modèle pourrait fabriquer une fermeture en réarrangeant les correspondances. P1 verrouille à l’avance la correspondance 20→4 et la détruit volontairement par un contrôle négatif shuffle précisément pour juger si le signal de fermeture dépend vraiment d’une correspondance physiquement raisonnable. |
5 | Modèles et méthode : que compare exactement P1 ?
5.1 Côté EFT : une réponse gravitationnelle moyenne de faible dimension
Le côté EFT utilise un terme de vitesse supplémentaire de faible dimension pour décrire la réponse gravitationnelle moyenne : la forme de ce terme est contrôlée par une fonction noyau sans dimension f(r/ℓ), où ℓ est une échelle globale, et son amplitude est donnée par RC-bin. Différentes fonctions noyau représentent des pentes initiales, des vitesses de transition et des queues à longue portée différentes ; elles servent aux tests de robustesse.
5.2 Côté DM : il faut distinguer la comparaison principale et l’annexe P1A
Dans la comparaison principale du texte, DM_RAZOR est une base NFW minimale et auditable : relation c–M fixe, sans halo-to-halo scatter, contraction adiabatique, feedback core, non-sphéricité ni terme environnemental. L’avantage de cette conception est un nombre de degrés de liberté contrôlé et une reproduction aisée ; sa limite est qu’elle ne peut pas représenter tous les modèles LambdaCDM ni tous les modèles de halos de matière noire.
Ainsi, dans l’annexe B (P1A), le côté DM est transformé en une série de « tests de résistance standardisés » : sans modifier la correspondance partagée ni le protocole de fermeture, on ajoute progressivement des branches d’amélioration de faible dimension telles que SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m et la base combinée DM_STD, tout en conservant EFT_BIN comme témoin. On peut comprendre P1A ainsi : il ne s’agit pas de comparer seulement avec une base DM minimale, mais de placer un ensemble de mécanismes DM courants et auditables sous la même « règle de fermeture ».
Formulation précise des conclusions adoptée ici |
Texte principal : la série EFT surpasse nettement le DM_RAZOR minimal dans la comparaison principale. |
Annexe B / P1A : sous plusieurs branches d’amélioration DM de faible dimension et auditables, ainsi que sous le test DM_STD, certains ajustements conjoints DM peuvent s’améliorer, mais la force de fermeture n’élimine pas l’avantage d’EFT_BIN. |
La formulation la plus prudente est donc la suivante : dans le périmètre des données, de la correspondance, du registre de paramètres et du protocole de fermeture de P1/P1A, la réponse gravitationnelle moyenne d’EFT montre une cohérence inter-données plus forte ; cela ne revient pas à exclure tous les modèles de matière noire. |
5.3 Test de fermeture : la grammaire expérimentale la plus importante de P1
1. Ajuster uniquement avec RC afin d’obtenir un ensemble d’échantillons postérieurs RC-only.
2. Ne pas autoriser de réajustement avec GGL ; utiliser directement les postérieurs RC pour prédire le GGL.
3. Calculer, avec la covariance complète, le score de prédiction GGL logL_true sous la correspondance correcte.
4. Permuter aléatoirement la correspondance RC-bin→GGL-bin et calculer le contrôle négatif logL_perm.
5. Soustraire les deux pour obtenir la force de fermeture : ΔlogL_closure = <logL_true> − <logL_perm>.
Analogie simple |
Le test de fermeture ressemble à une épreuve de rattrapage sur un autre terrain d’examen : le modèle apprend d’abord une régularité dans la salle RC, puis répond dans la salle GGL. S’il a vraiment appris une régularité partagée, et non une astuce locale, il devrait encore bien répondre après changement de salle ; si l’on mélange volontairement les correspondances entre salles, l’avantage devrait disparaître. |
5.4 Avant de lire les tableaux techniques : retenir quatre points d’entrée
Tableau 5.4 | Parcours de lecture de la prochaine série de tableaux techniques en format paysage
Entrée | Ce qu’il faut regarder | Pourquoi c’est important |
Tableau S1a | Score total de l’ajustement conjoint RC+GGL | Répond à la question : « en regardant les deux jeux de données ensemble, qui offre l’explication globale la plus forte ? » |
Tableau S1b | Force de fermeture, shuffle, balayages de robustesse | Répond à la question : « ce qui est appris sur RC peut-il être transféré au GGL ? » |
Tableau B0 | Définition des multiples branches d’amélioration DM dans P1A | Évite de réduire P1 à une comparaison « seulement avec le DM_RAZOR minimal ». |
Tableau B1 | Scoreboard de fermeture et d’ajustement conjoint de P1A | Vérifie si l’avantage de fermeture disparaît après renforcement de DM. |
Note de mise en page |
Les pages suivantes passent en format paysage afin de conserver intégralement les tableaux larges du rapport original, sans supprimer de colonnes ni les compresser jusqu’à les rendre illisibles. Le texte explicatif a déjà donné une lecture accessible ; les tableaux techniques en paysage s’adressent à ceux qui veulent vérifier les chiffres et les branches de modèles. |
Figure 0.1 | Comprendre en une figure le processus de test de fermeture de P1
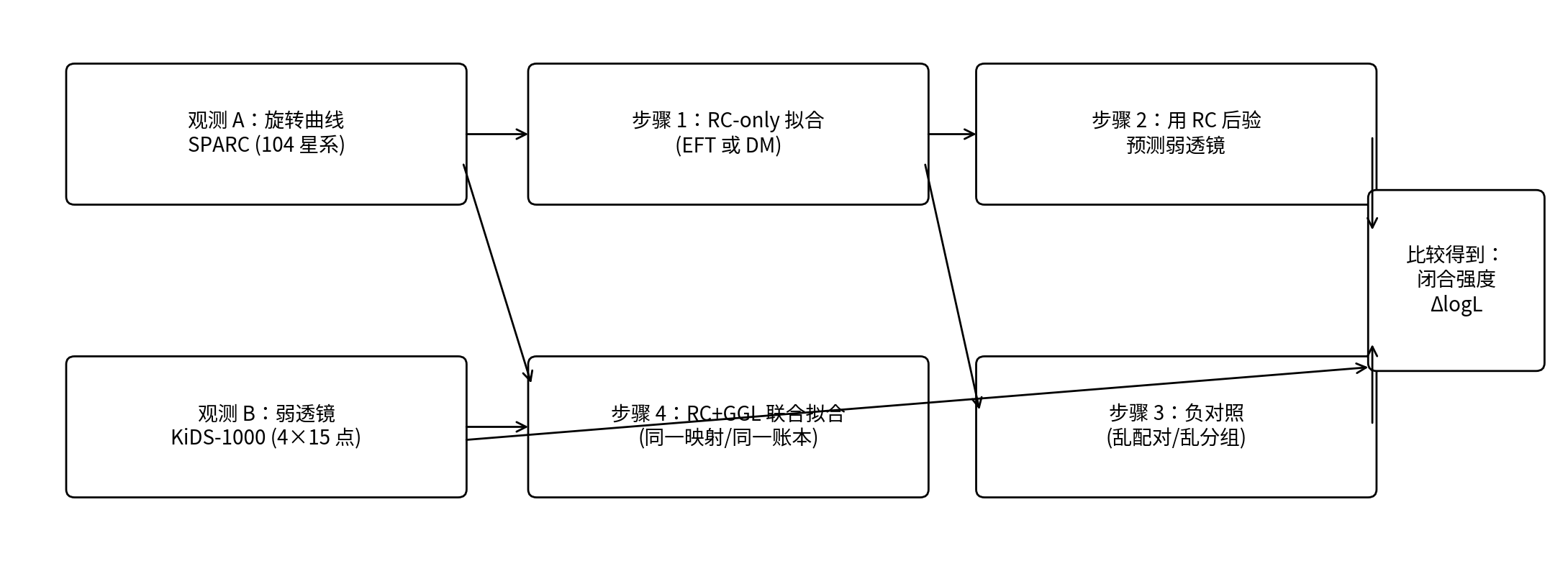
Note : la chaîne supérieure correspond au « test de fermeture » (ajustement avec RC seulement → prédiction du GGL à partir du postérieur RC) ; la chaîne inférieure correspond à l’« ajustement conjoint » (RC+GGL évalués ensemble). À droite, la correspondance réelle est comparée à la correspondance mélangée afin d’obtenir la force de fermeture ΔlogL.
6 | Tableaux techniques clés : tableaux principaux du rapport original et tableaux P1A
Tableau S1a | Indicateurs principaux de comparaison en ajustement conjoint (RC+GGL, Strict ; conservé du rapport original)
Modèle (workspace) | Noyau W | k | logL_total conjoint (best) | ΔlogL_total vs DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tableau S1b | Indicateurs de fermeture et de robustesse (Strict ; conservé du rapport original)
Modèle (workspace) | ΔlogL de fermeture (true-perm) | ΔlogL après shuffle du contrôle négatif | Plage de ΔlogL sous balayage σ_int | Plage de ΔlogL sous balayage R_min | Plage de ΔlogL sous balayage cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
Tableau B0 | Définition des branches d’amélioration DM dans P1A (conservé de l’annexe B du rapport original)
Workspace | dm_model | Nouveau paramètre (≤1) | Motivation physique (cœur) | Principe d’implémentation (audit-friendly) |
|---|---|---|---|---|
DM_RAZOR | NFW (fixed c–M, no scatter) | — | Base de halo LambdaCDM minimale et auditable ; utilisée pour une comparaison stricte avec EFT | Correspondance partagée fixe ; registre de paramètres strict ; baseline utilisée uniquement pour comparaison relative |
DM_RAZOR_SCAT | NFW + c–M scatter(legacy) | σ_logc | La relation c–M présente une dispersion ; approximation par un scatter log-normal à un paramètre | ≤1 nouveau paramètre ; correspondance partagée conservée ; gain de fermeture comme critère de validation |
DM_RAZOR_AC | NFW + Adiabatic Contraction(legacy) | α_AC | L’infall baryonique peut provoquer une contraction adiabatique du halo ; approximation par une intensité à un paramètre | ≤1 nouveau paramètre ; correspondance inchangée ; rapport des variations AICc/BIC et du gain de fermeture |
DM_RAZOR_FB | NFW + feedback core(legacy) | log r_core | Le feedback peut former un core dans la région interne ; approximation par une échelle de core à un paramètre | ≤1 nouveau paramètre ; même protocole pour fermeture et contrôle négatif ; l’amélioration RC-only n’est pas l’unique objectif |
DM_HIER_CMSCAT | Hierarchical c–M scatter + prior | σ_logc(hier) | Hiérarchisation plus standard c_i∼logN(c(M_i),σ_logc) ; affecte simultanément le postérieur conjoint RC et GGL | Prior explicite ; marginalisation des c_i latents ; faible dimension et auditabilité conservées |
DM_CORE1P | 1‑parameter core proxy (coreNFW/DC14‑inspired) | log r_core | Utilise un proxy core à un paramètre pour représenter l’effet principal du baryonic feedback, en évitant les détails de formation stellaire de haute dimension | Références standard citées ; ≤1 nouveau paramètre ; lié au test de fermeture |
DM_RAZOR_M | NFW + lensing shear‑calibration nuisance | m_shear(GGL) | Absorbe une systématique clé du côté lentillage faible par un paramètre effectif, afin de réduire le risque de « prendre une erreur systématique pour de la physique » | Paramètre de nuisance explicitement enregistré ; aucun effet inverse autorisé sur RC ; les résultats privilégient la robustesse de fermeture |
DM_STD | Standardized DM baseline (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Intègre simultanément les trois objections courantes les plus fréquentes dans une base standard qui reste de faible dimension | Registre des paramètres et critères d’information rapportés ensemble ; fermeture comme indicateur principal ; utilisé comme contrôle défensif DM le plus fort |
Tableau B1 | Scoreboard P1A (plus la valeur est élevée, mieux c’est ; conservé de l’annexe B du rapport original)
Branche de modèle (workspace) | Δk | RC-only best logL_RC (Δ) | Force de fermeture ΔlogL_closure (Δ) | Joint best logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Comment lire le tableau B1 (scoreboard P1A) |
• Δk : degrés de liberté ajoutés (plus c’est grand, plus le modèle est complexe ; plus complexe ne signifie pas meilleur). • Regarder surtout deux colonnes : la force de fermeture ΔlogL_closure(Δ) (plus elle est grande, plus la « transférabilité est auto-cohérente ») et Joint best logL_total(Δ) (score total de l’ajustement conjoint). • Le (Δ) entre parenthèses indique l’écart par rapport à DM_RAZOR, pour faciliter la comparaison directe. |
• La question principale de ce tableau est : lorsque la base DM est « raisonnablement renforcée », l’avantage de fermeture disparaît-il ? • Indice de lecture : le score conjoint de DM_STD s’améliore nettement, mais sa force de fermeture diminue ; EFT_BIN conserve une force de fermeture plus élevée. |
Résumé en une phrase : dans cet ensemble d’améliorations DM de faible dimension et auditables, améliorer l’ajustement conjoint ne produit pas automatiquement une fermeture plus forte ; la fermeture, c’est-à-dire la transférabilité, reste le critère clé. |
7 | Comment lire les principaux résultats ?
7.1 Ajustement conjoint : en regardant les deux jeux de données ensemble, EFT obtient un meilleur score dans la comparaison principale
Le tableau S1a et la figure S4 montrent qu’avec les mêmes données, la même correspondance partagée et une échelle de paramètres à peu près comparable, la série EFT obtient, par rapport à DM_RAZOR, un ΔlogL_total conjoint de 1155–1337. Pour un lecteur général, cela signifie que, sous la même règle de score appliquée aux données RC et GGL réunies, les modèles EFT de la comparaison principale obtiennent un score total plus élevé.
7.2 Test de fermeture : ce que P1 veut surtout souligner, c’est la « transférabilité »
Une force de fermeture élevée indique que les paramètres inférés par le modèle à partir de RC seulement peuvent mieux prédire le GGL sans que le modèle ne revoie le GGL. Dans le rapport P1, le ΔlogL_closure d’EFT est de 172–281, contre 127 pour DM_RAZOR. Ce résultat est plus important que le simple fait que « chaque ajustement soit bon », car il limite la liberté du modèle sur le second jeu de données.
7.3 Contrôle négatif : pourquoi l’« effondrement du signal » est-il au contraire une bonne chose ?
Après permutation aléatoire de la correspondance par groupes RC-bin→GGL-bin, le signal de fermeture d’EFT tombe à l’ordre de 6–23. Pour un lecteur général, cette étape sert d’« anti-triche » : si l’avantage de fermeture venait seulement du code, des unités, de la covariance ou d’un hasard d’ajustement, il pourrait subsister même après mélange des correspondances. Or l’avantage s’effondre, ce qui montre qu’il dépend de la bonne correspondance.
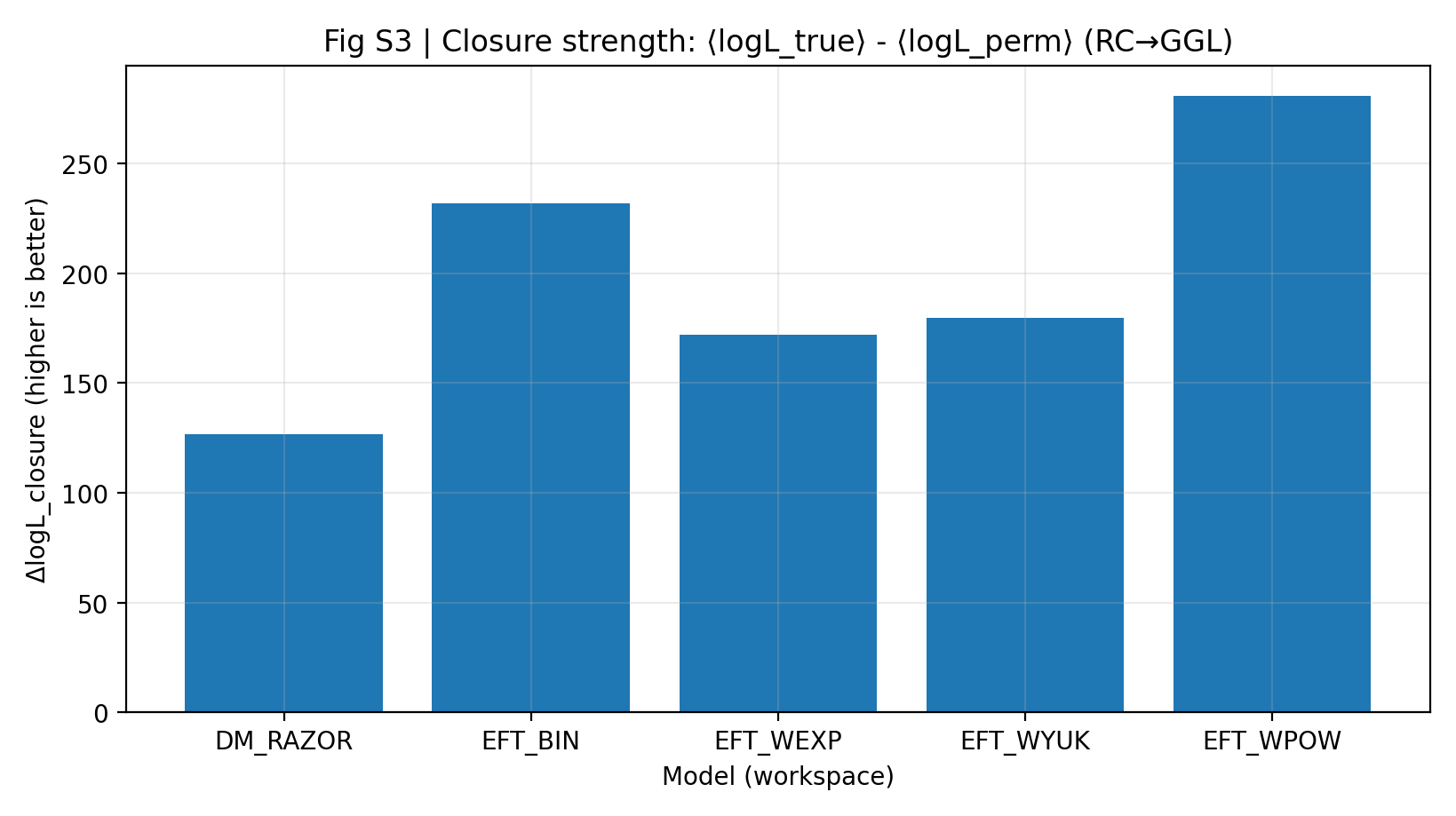
Figure S3 | Force de fermeture (plus c’est élevé, mieux c’est) : avantage moyen en log-vraisemblance de la prédiction RC-only → GGL.
Comment lire cette figure |
Cette figure est le cœur de P1. Plus la barre est haute, plus l’information apprise par le modèle à partir des RC se transfère au GGL. |
La série EFT est globalement au-dessus de DM_RAZOR, ce qui indique que, dans l’expérience « apprendre d’abord sur RC, puis prédire GGL », la fermeture inter-sondes d’EFT est plus forte. |
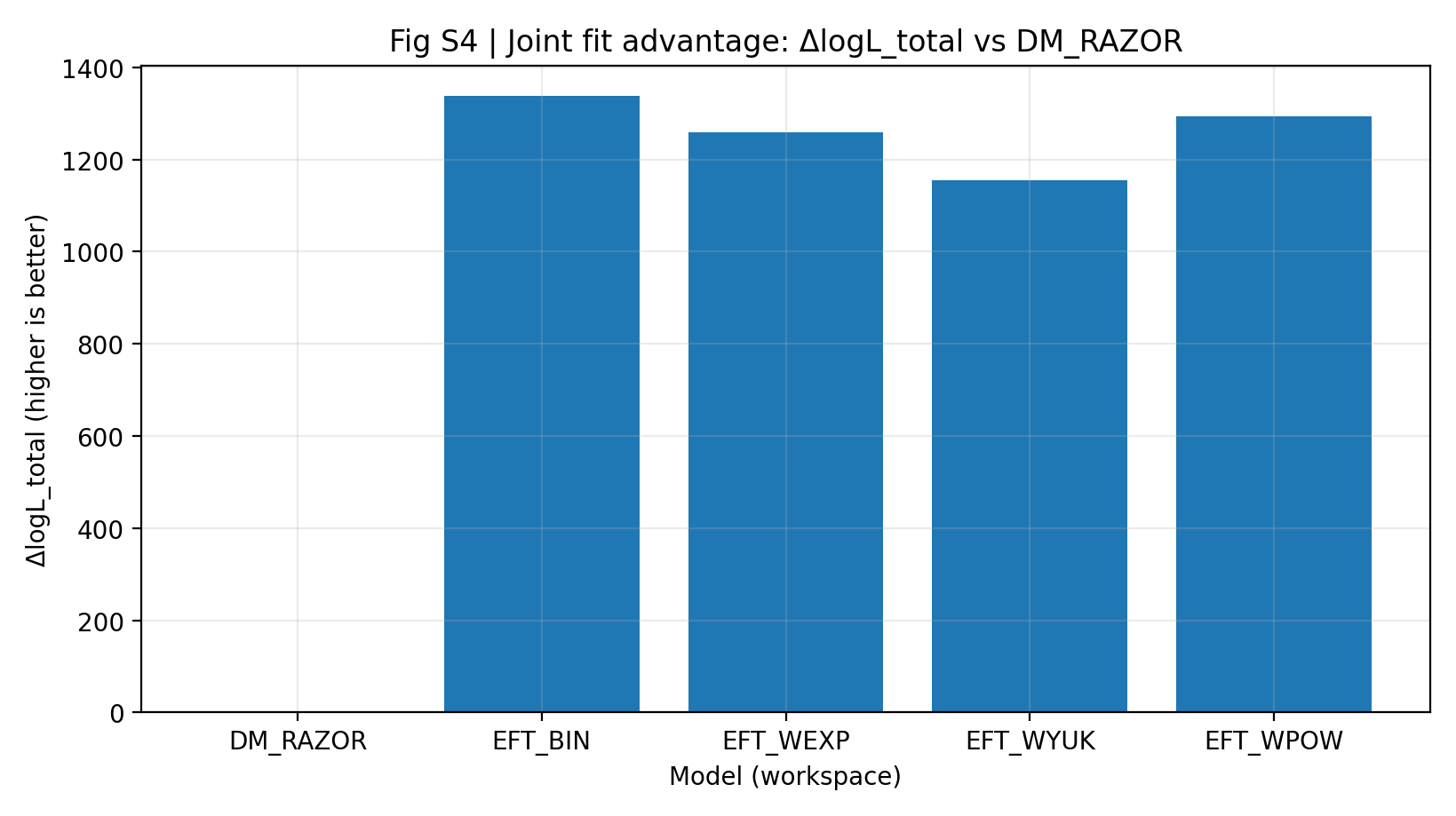
Figure S4 | Avantage en ajustement conjoint (plus c’est élevé, mieux c’est) : best logL_total de RC+GGL par rapport à DM_RAZOR.
Comment lire cette figure |
Cette figure examine le score total après combinaison de RC et GGL. |
Toute la série EFT est nettement au-dessus de 0, ce qui indique que l’avantage d’EFT dans la comparaison principale n’est pas un phénomène local isolé, mais la performance globale de l’analyse conjointe. |
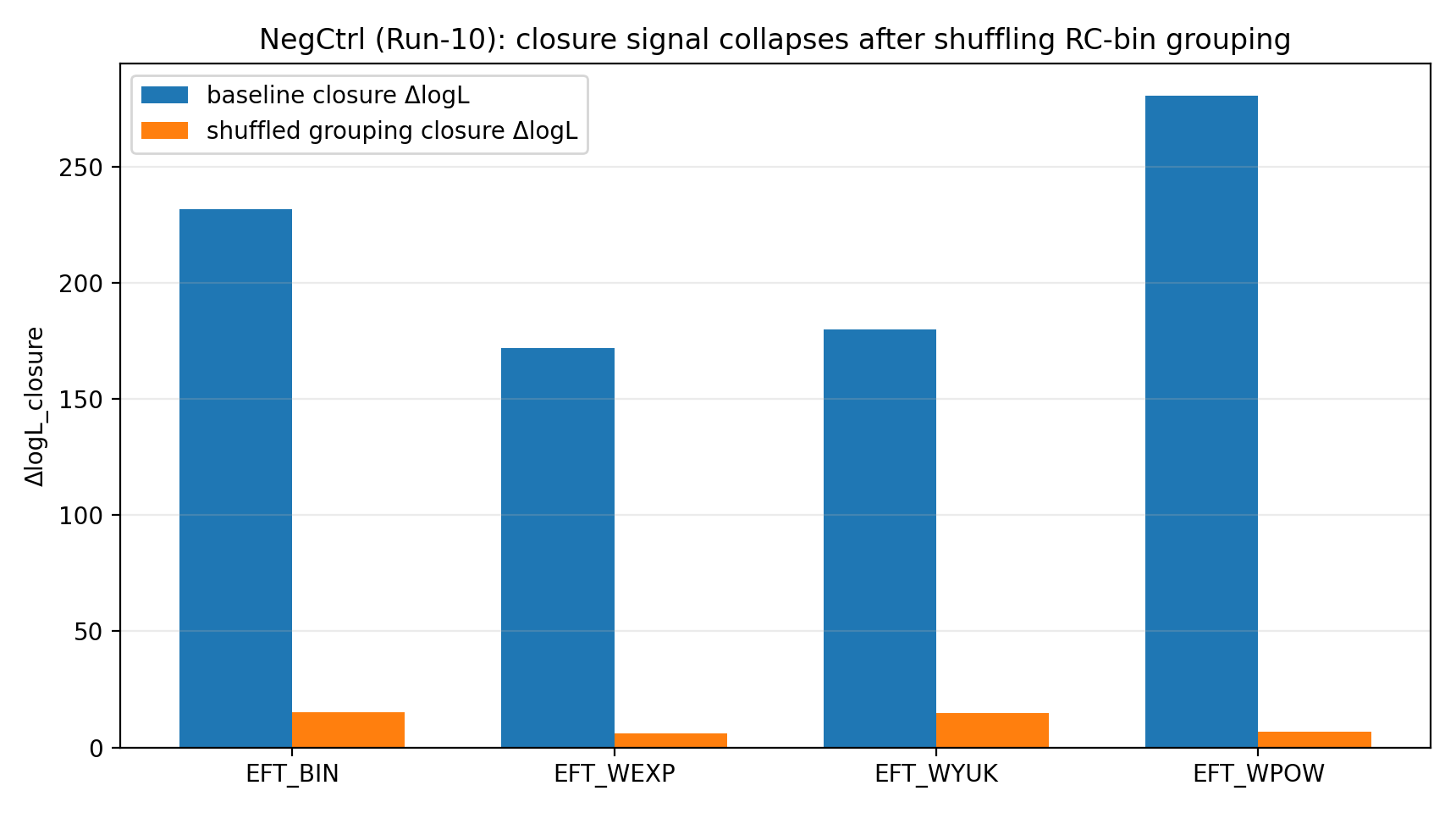
Figure R1 | Contrôle négatif : le signal de fermeture diminue fortement après shuffle des groupes.
Comment lire cette figure |
Cette figure montre qu’une fois la bonne relation de binning RC↔GGL mélangée, le signal de fermeture diminue fortement. |
Cela rend les résultats de P1 plus proches d’une cohérence réelle dans une correspondance inter-données, plutôt que d’une coïncidence numérique que n’importe quelle correspondance pourrait produire. |
8 | Robustesse et contrôles : comment P1 évite-t-il l’objection d’un simple « bel ajustement par paramètres » ?
La critique la plus naturelle d’un rapport technique est la suivante : l’avantage vient-il d’un réglage de bruit, d’un segment de données du centre galactique, d’un traitement particulier de la covariance ou d’un surajustement ? P1 répond à cette question par plusieurs séries de tests de résistance.
Tableau 2 | Lecture des tests de robustesse et des contrôles négatifs de P1
Test | Question qu’il cherche à écarter | Lecture |
Balayage σ_int | Si les RC contiennent une dispersion inconnue supplémentaire, la conclusion reste-t-elle stable ? | Après élargissement des erreurs RC, le classement d’EFT et l’ordre de grandeur de son avantage restent stables. |
Balayage R_min | Si l’on ne fait pas entièrement confiance aux régions centrales des galaxies, la conclusion reste-t-elle stable ? | Après coupure des régions centrales, EFT conserve un avantage positif. |
Balayage cov-shrink | Si l’estimation de la covariance GGL est incertaine, la conclusion reste-t-elle stable ? | Après contraction de la covariance vers une matrice diagonale, l’avantage est peu sensible. |
Échelle d’ablation | EFT obtient-elle son ajustement grâce à une complexité inutile ? | L’EFT_BIN complet est justifié par les critères d’information. |
Prédiction LOO avec bin laissé de côté | Le modèle ne sait-il expliquer que les données déjà vues ? | Après exclusion d’un bin GGL, il montre encore une bonne capacité de généralisation. |
RC-bin shuffle | La fermeture provient-elle d’une correspondance réelle ? | Après mélange des groupes, la fermeture diminue, ce qui soutient la dépendance à la correspondance. |
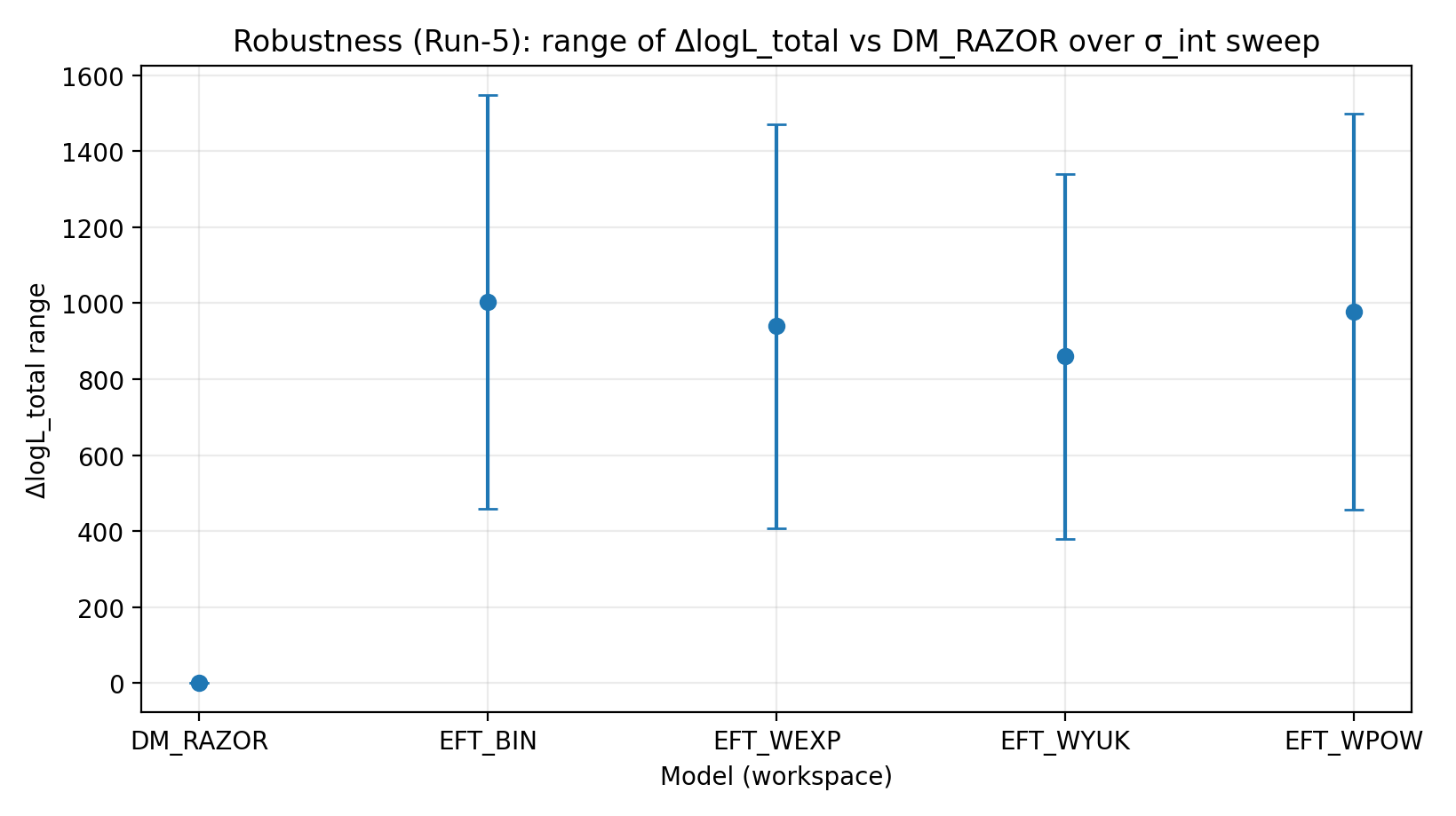
Figure R2 | Plage de ΔlogL_total sous balayage de σ_int (plus c’est élevé, mieux c’est).
Comment lire cette figure |
Teste si l’avance d’EFT subsiste lorsque le réglage de dispersion intrinsèque des RC varie. |
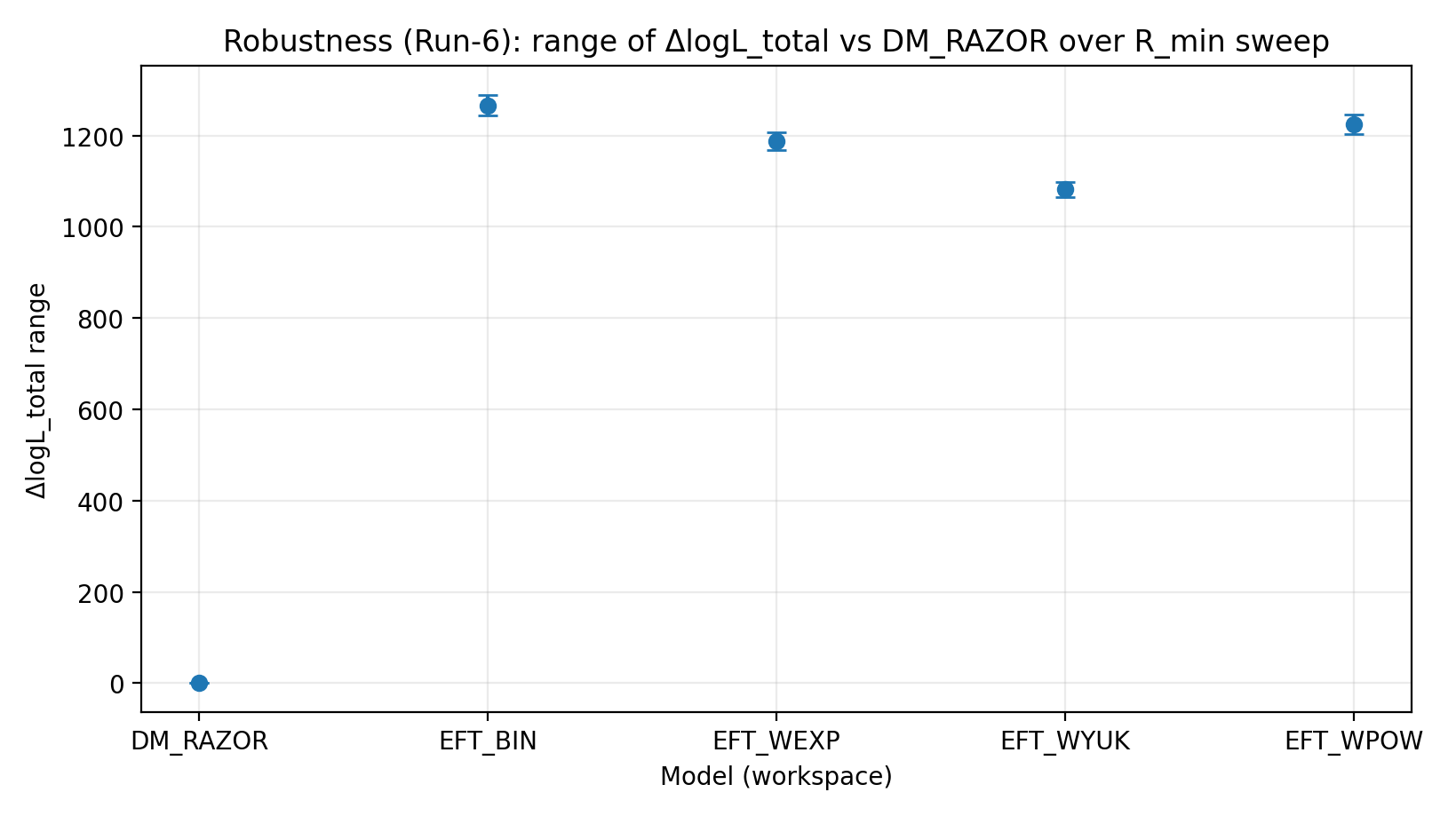
Figure R3 | Plage de ΔlogL_total sous balayage de R_min (plus c’est élevé, mieux c’est).
Comment lire cette figure |
Teste si l’avantage d’EFT reste stable après coupe des régions centrales complexes. |
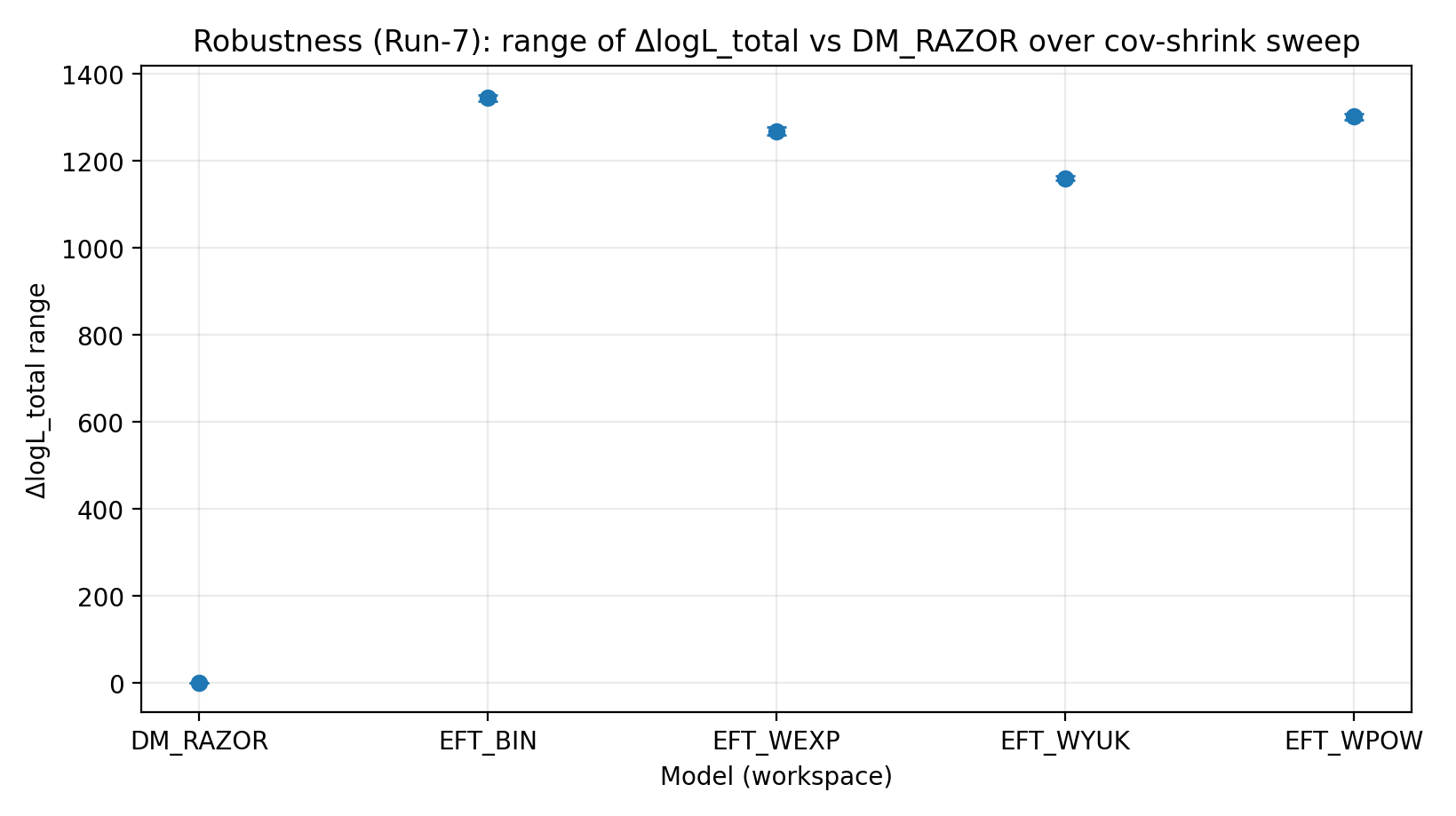
Figure R4 | Plage de ΔlogL_total sous balayage cov-shrink (plus c’est élevé, mieux c’est).
Comment lire cette figure |
Teste si le classement est sensible aux changements de traitement de la covariance du lentillage faible. |
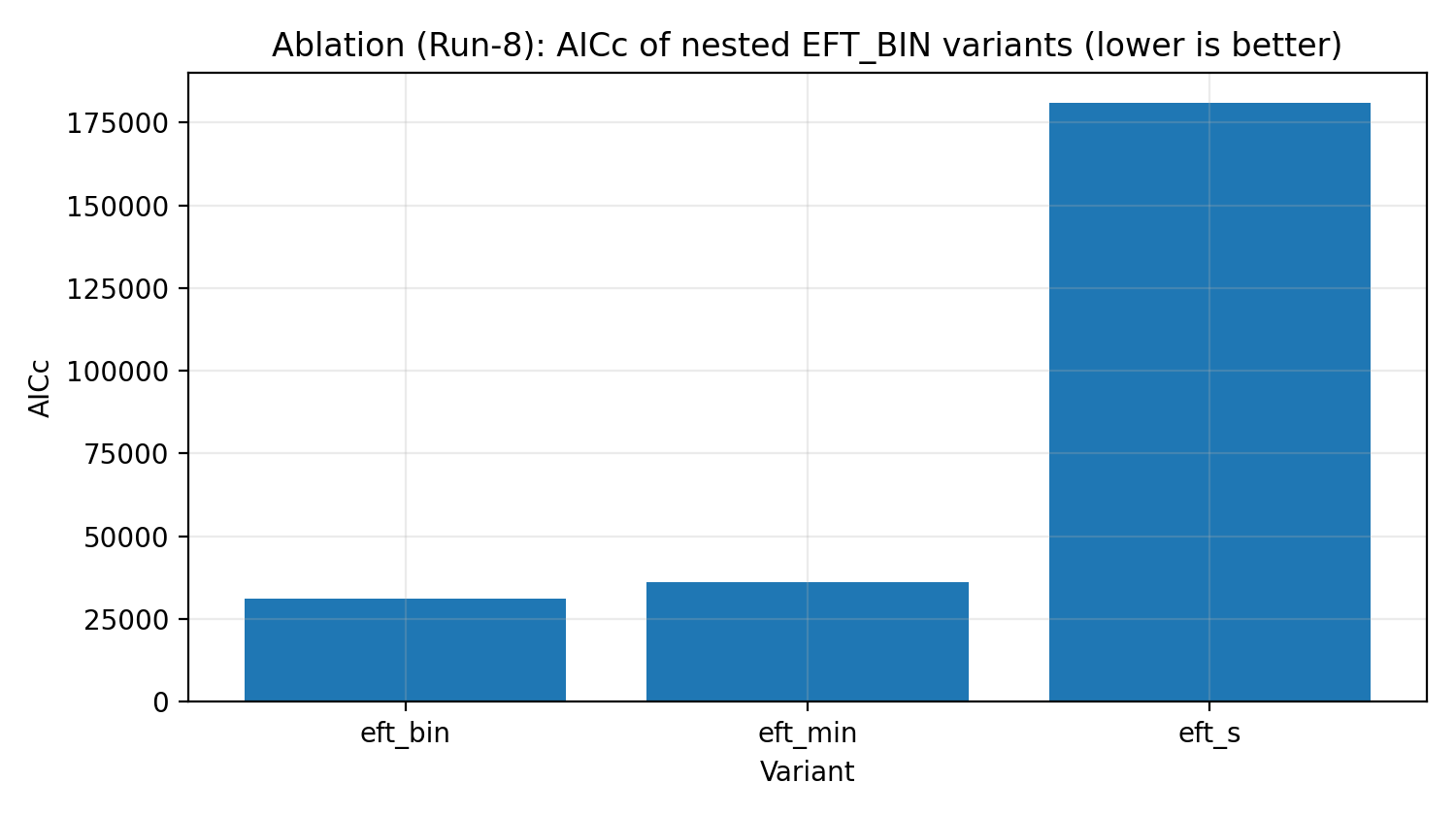
Figure R5 | Échelle d’ablation d’EFT_BIN (AICc, plus c’est faible, mieux c’est).
Comment lire cette figure |
Teste si l’EFT_BIN complet est nécessaire pour expliquer les données, plutôt qu’un simple ajout gratuit de paramètres. |
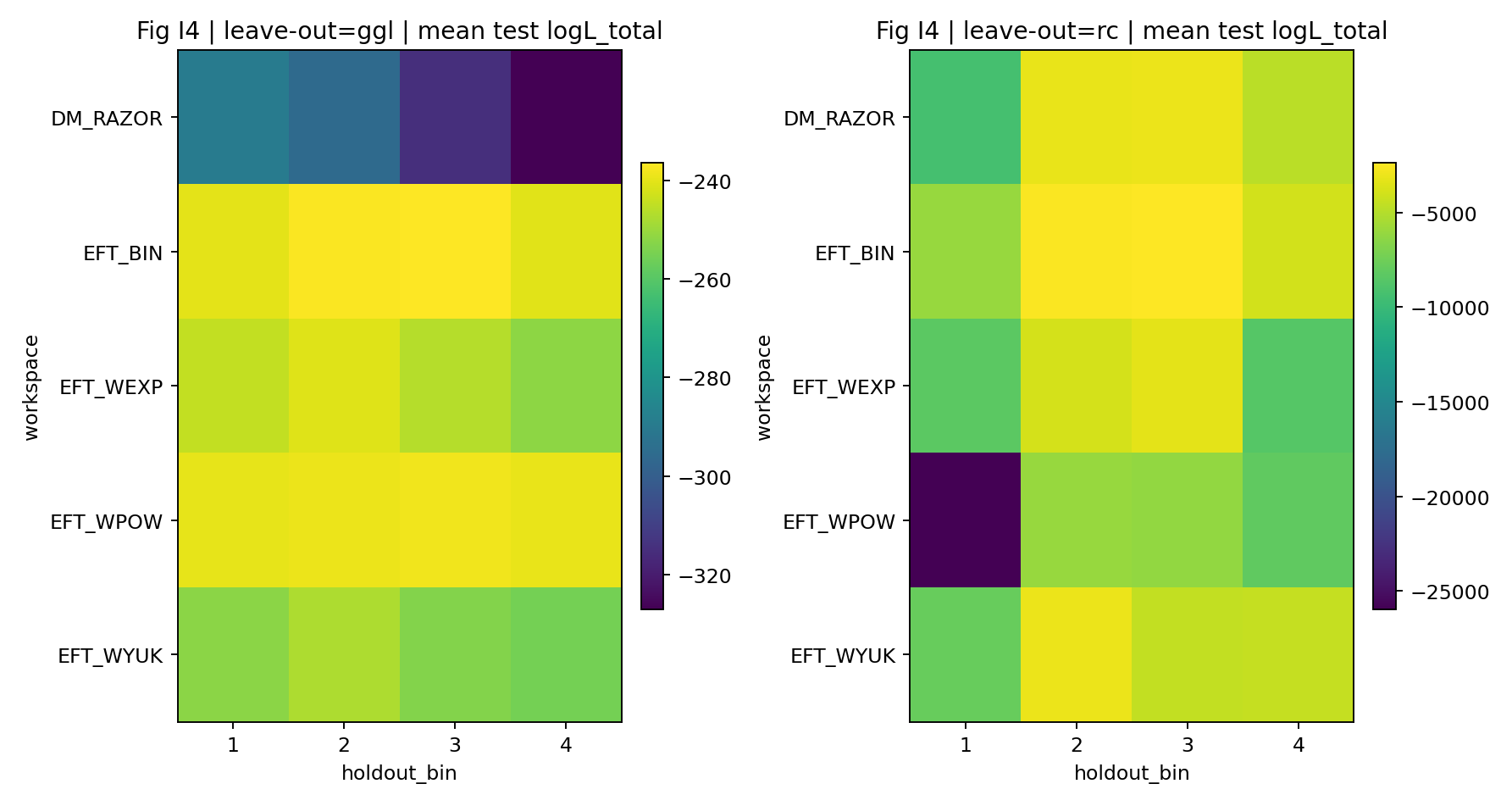
Figure R6 | LOO : distribution de la log-vraisemblance des bins laissés de côté.
Comment lire cette figure |
Teste si le modèle conserve une capacité prédictive sur des bins GGL non vus. |
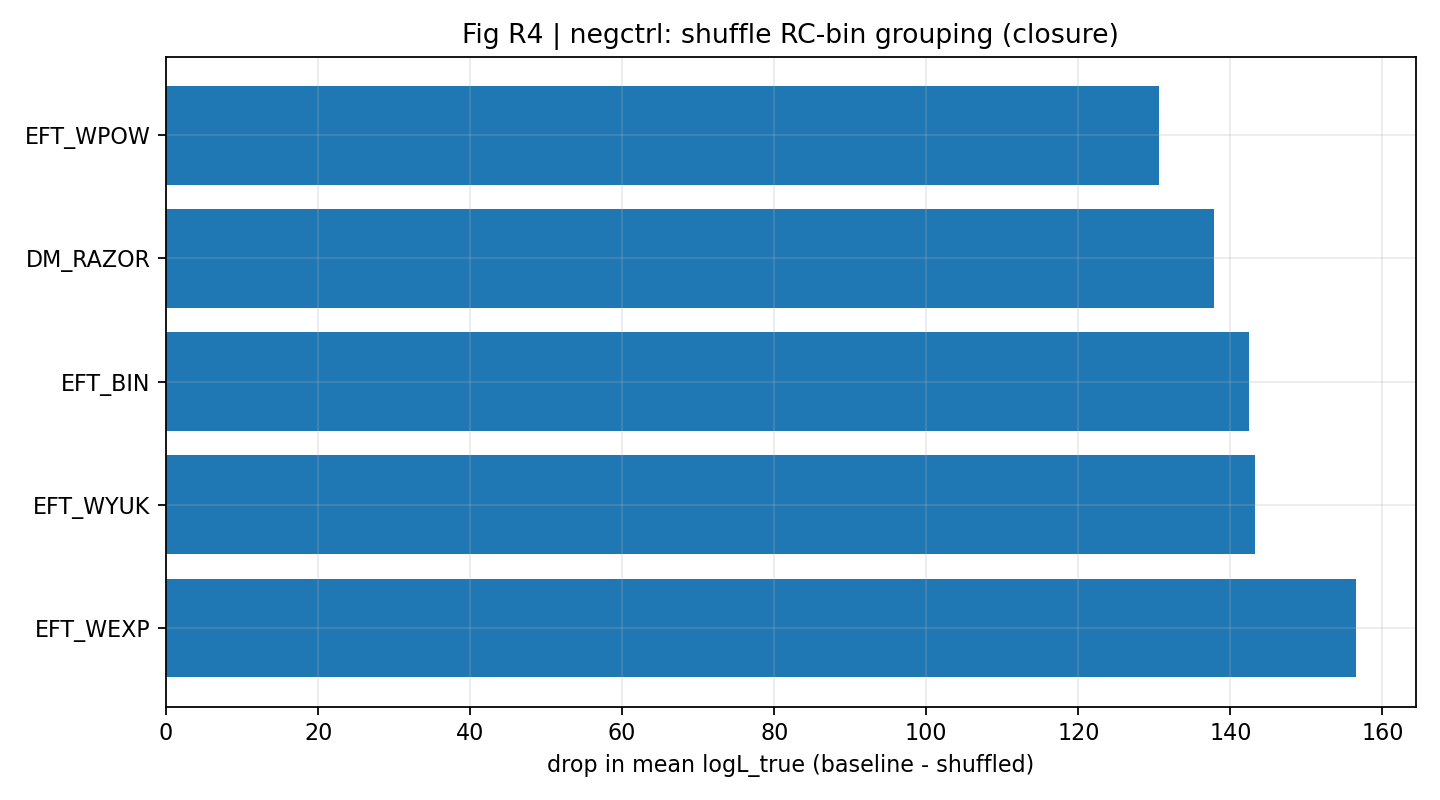
Figure R7 | Contrôle négatif : le shuffle de la correspondance entraîne une forte baisse du mean logL_true de fermeture.
Comment lire cette figure |
Montre en outre, du point de vue du mean logL_true, que la fermeture dépend de la bonne correspondance inter-données. |
9 | P1A : pourquoi la présence de plusieurs modèles DM en annexe est-elle une correction essentielle ?
Cette section ne répond pas à la question : « EFT n’a-t-elle battu qu’un DM_RAZOR minimal ? » Elle demande plutôt si les conclusions du test de fermeture et de l’ajustement conjoint seraient réécrites lorsque l’on renforce la base DM dans un espace de faible dimension, reproductible et doté d’un registre de paramètres clair (P1A). Autrement dit, l’objectif de P1A est d’atténuer l’objection « vous avez simplement choisi une base DM trop faible » et de déplacer la discussion vers la question : « sous un ensemble d’améliorations DM auditables, les performances de fermeture restent-elles différentes ? »
La conception de P1A ne cherche pas à épuiser toutes les possibilités de modélisation des halos LambdaCDM, ni à transformer le côté DM en ajusteur de haute dimension impossible à auditer. Elle retient des améliorations de faible dimension, reproductibles et clairement enregistrées : scatter de concentration, contraction adiabatique, feedback core, prior hiérarchique c–M scatter, proxy core à un paramètre, paramètre de nuisance de calibration du shear en lentillage faible, ainsi que la combinaison DM_STD.
Lecture principale de P1A |
Parmi les trois branches legacy, seul feedback/core apporte un léger gain net de force de fermeture ; SCAT et AC n’apportent pas de gain net de fermeture. |
DM_HIER_CMSCAT, DM_RAZOR_M et DM_CORE1P ont peu d’effet sur la force de fermeture, ou ne montrent pas de gain net significatif. |
DM_STD peut améliorer fortement le joint logL, mais sa force de fermeture diminue ; cela suggère qu’il augmente surtout la flexibilité de l’ajustement conjoint, plutôt que la puissance de prédiction transférée RC→GGL. |
Dans le tableau B1 de P1A, EFT_BIN conserve une force de fermeture et un avantage d’ajustement conjoint plus élevés ; le cœur de la proposition de P1 ne doit donc pas être réduit à « avoir seulement battu le DM_RAZOR minimal ». |
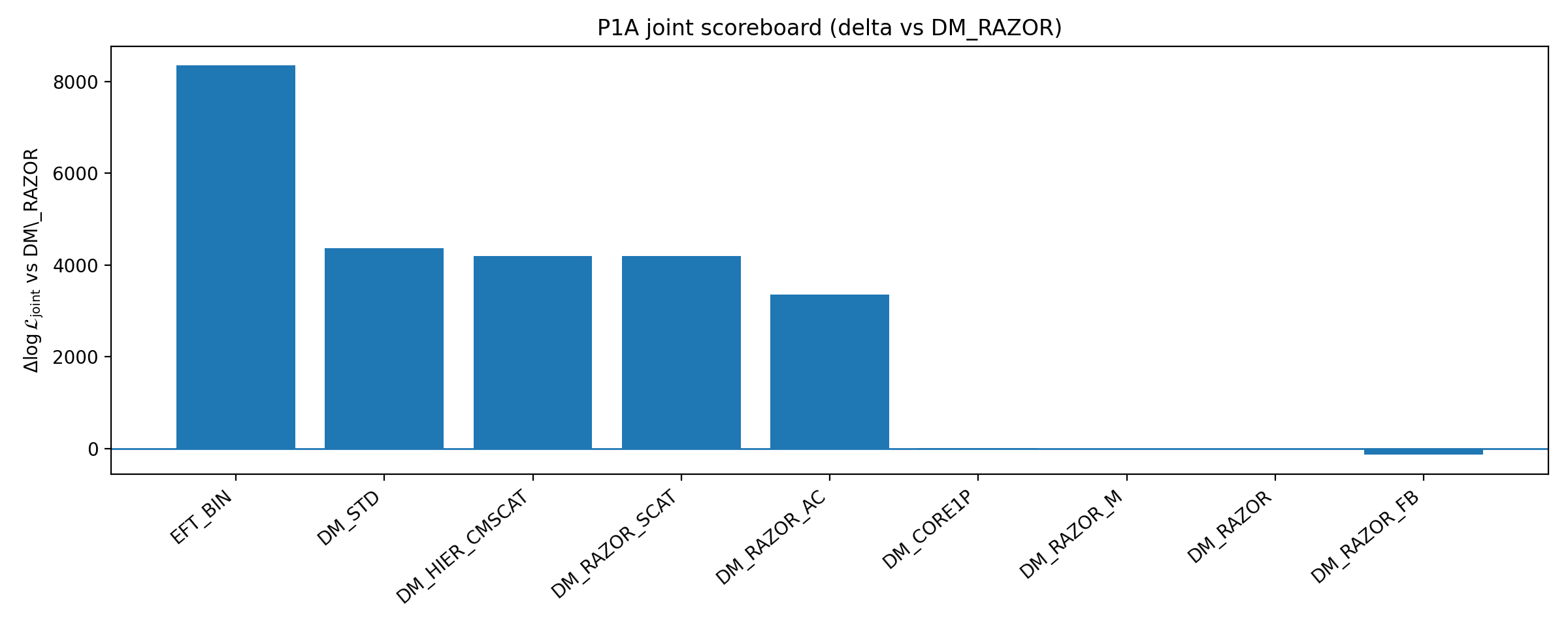
Figure B1 | Scoreboard P1A : ΔlogL de fermeture et conjoint par rapport à la baseline (plus c’est élevé, mieux c’est).
Comment lire cette figure |
Cette figure montre la performance de plusieurs branches d’amélioration DM par rapport à la base. |
Son sens n’est pas « exclure toute DM », mais montrer que, dans la plage d’améliorations DM de faible dimension et auditables choisie par P1A, renforcer DM n’élimine pas l’avantage de fermeture d’EFT_BIN. |
10 | Signification de l’expérience P1 : pourquoi cela vaut-il la peine ?
10.1 Signification méthodologique : placer la « fermeture inter-sondes » au-dessus de l’« ajustement sur une seule sonde »
Les théories à l’échelle galactique tombent facilement dans le débat suivant : un modèle peut-il ajuster tel ensemble de courbes de rotation ? P1 élève la question d’un niveau : les paramètres appris à partir des RC peuvent-ils prédire le lentillage faible sans réajuster le GGL ? P1 passe ainsi d’un « concours d’ajustement » à un « test de prédiction transférée ».
10.2 Signification pour la transparence : traiter la chaîne vérifiable comme une partie du résultat
Une contribution importante de P1 est de publier ensemble les données, tableaux et figures, étiquettes d’exécution, contrôles négatifs, paquet de reproduction et chaîne d’audit. C’est essentiel pour les partisans comme pour les critiques : la discussion peut revenir au même jeu de données publiques, à la même correspondance, aux mêmes scripts et aux mêmes indicateurs, au lieu de comparer seulement des slogans.
10.3 Signification physique : un test de résistance fort pour les approches gravitationnelles sans matière noire
Dans les approches gravitationnelles sans matière noire, de nombreux modèles peuvent expliquer une partie des courbes de rotation ou de la RAR ; le plus difficile est de réussir en même temps les lectures de lentillage faible et de montrer, sous contrôle négatif, que le signal dépend de la bonne correspondance. L’importance de P1 est de placer la réponse gravitationnelle moyenne d’EFT dans un protocole proche d’un « examen externe » : RC est le terrain d’entraînement, GGL le terrain de transfert, shuffle le terrain anti-triche.
10.4 Est-ce une expérience importante pour le domaine de la gravité sans matière noire ?
Avec prudence : si le traitement des données, le paquet de reproduction et le protocole de fermeture de P1 tiennent après vérification externe, P1 peut être considéré comme une expérience de fermeture RC+GGL à prendre au sérieux dans les approches de gravité sans matière noire ou de gravité modifiée. Son importance ne tient pas à la formule « renverser la matière noire », mais au fait qu’il propose un critère inter-sondes reproductible, contestable et extensible.
Existe-t-il déjà un cadre de prédiction RC+GGL avec une fermeture aussi élevée ? |
Il existe déjà des cadres et traditions observationnelles pertinentes : MOND/RAR organise très bien de nombreux phénomènes de courbes de rotation ; le travail RAR en lentillage faible KiDS-1000 a aussi comparé MOND, la gravité émergente de Verlinde et des modèles LambdaCDM ; LambdaCDM peut également expliquer une partie des phénomènes de lentillage faible et de dynamique via la connexion galaxie–halo, les halos gazeux et la modélisation du feedback. |
Mais la revendication précise de P1 n’est pas qu’« aucun autre cadre au monde ne puisse expliquer RC+GGL ». Elle est que, dans le protocole public propre à P1 — correspondance fixe, fermeture RC-only→GGL, contrôle négatif shuffle, registre des paramètres et tests de résistance P1A multi-DM — EFT rapporte une performance de fermeture plus forte. |
Autrement dit, ce qui mérite le plus d’être vérifié par l’extérieur dans P1, c’est la proposition d’un protocole de comparaison concret et reproductible. La prochaine étape, très importante, est de savoir si MOND/RAR, LambdaCDM/HOD, des simulations hydrodynamiques ou d’autres cadres de gravité modifiée peuvent atteindre, sous le même protocole, des scores de fermeture identiques ou supérieurs. |
11 | Que peut-on conclure de P1 ? Que ne peut-on pas conclure ?
Tableau 3 | Frontières des conclusions de P1
Ce que l’on peut conclure | Sous les données RC+GGL, la correspondance fixe et le protocole principal de comparaison de P1, la série EFT présente un ajustement conjoint et une force de fermeture plus élevés que le DM_RAZOR minimal. |
Ce que l’on peut conclure | Dans la plage d’améliorations DM de faible dimension et auditables de P1A, plusieurs améliorations DM n’éliminent pas l’avantage de fermeture d’EFT_BIN. |
Ce que l’on peut conclure | Le contrôle négatif shuffle montre que le signal de fermeture dépend de la bonne correspondance inter-données, et non d’une correspondance arbitraire. |
Ce que l’on ne peut pas conclure | On ne peut pas dire que P1 ait déjà renversé tous les modèles de matière noire. P1A n’épuise toujours pas la non-sphéricité, la dépendance environnementale, les connexions galaxie–halo complexes, le feedback de haute dimension ni les simulations cosmologiques complètes. |
Ce que l’on ne peut pas conclure | On ne peut pas dire que la théorie EFT complète ait été prouvée à partir de premiers principes. P1 ne teste que la couche phénoménologique de la réponse gravitationnelle moyenne. |
Ce que l’on ne peut pas conclure | On ne peut pas dire que toutes les erreurs systématiques aient été exclues. P1 fournit seulement des éléments de robustesse dans le périmètre des tests de résistance et de l’audit explicitement listés. |
12 | Questions fréquentes : les questions que les lecteurs généraux posent le plus volontiers
Q1 : Est-ce que cela signifie que « la matière noire n’existe pas » ?
Non. Les conclusions de P1 doivent être limitées aux données, au protocole et aux modèles de comparaison de ce document. P1A va déjà au-delà du DM_RAZOR minimal, mais ne représente toujours pas tous les modèles possibles de matière noire.
Q2 : Est-ce que cela signifie que « EFT est déjà prouvée » ?
Non plus. P1 teste EFT comme une paramétrisation de la réponse gravitationnelle moyenne et montre une performance plus forte dans la fermeture RC→GGL ; les mécanismes microscopiques et la théorie complète ne font pas partie des conclusions de P1.
Q3 : Pourquoi ne pas donner directement une significativité en σ ?
P1 utilise des scores de vraisemblance unifiés, des critères d’information et des différences de fermeture. ΔlogL est un avantage relatif sous la même règle de score ; ce n’est pas équivalent à une valeur unique en σ.
Q4 : Pourquoi mélanger RC-bin→GGL-bin ?
C’est un contrôle négatif. Un véritable signal inter-sondes devrait dépendre de la bonne correspondance ; s’il restait aussi fort après mélange, cela indiquerait plutôt un biais d’implémentation ou un faux signal statistique.
Q5 : Quelle devrait être la prochaine étape la plus importante pour P1 ?
Étendre le même protocole à davantage de données, de contrôles DM, de systématiques plus complexes et de cadres de gravité modifiée plus nombreux ; surtout, permettre à des équipes externes de le retester avec le même indicateur de fermeture.
13 | Petit glossaire
Tableau 4 | Petit glossaire
Terme | Explication en une phrase |
Courbes de rotation (RC) | Relation rayon–vitesse dans un disque galactique, utilisée pour inférer la gravité effective dans le plan du disque. |
Lentillage faible (GGL) | Mesure la distribution moyenne de gravité ou de masse autour des galaxies d’avant-plan à partir de la distorsion statistique des formes de galaxies d’arrière-plan. |
Test de fermeture | Utilise le postérieur RC pour prédire le GGL et compare avec un contrôle négatif où la correspondance est mélangée. |
Contrôle négatif | Détruit volontairement une structure clé pour voir si le signal disparaît ; sert à écarter les faux signaux. |
Halo NFW | Profil de densité de halo de matière noire couramment utilisé dans les modèles de matière noire froide. |
Relation c–M | Relation entre la concentration c d’un halo de matière noire et sa masse M ; autoriser ou non le scatter influence la flexibilité du modèle. |
DM_STD | Branche standardisée de test de résistance DM dans P1A, combinant plusieurs améliorations DM de faible dimension avec un paramètre de nuisance de lentillage. |
ΔlogL | Différence de log-vraisemblance entre deux modèles sous la même règle de score ; une valeur positive indique que le premier est meilleur. |
Covariance | Description matricielle des corrélations entre points de données ; les données de lentillage faible nécessitent généralement la covariance complète. |
14 | Parcours de lecture recommandé et points d’entrée pour les citations
1. Lire d’abord les sections 0–2 afin de saisir la problématique de P1 et le positionnement volontairement retenu d’EFT dans P1.
2. Lire ensuite les figures S3, S4 et les tableaux S1a/S1b pour comprendre la force de fermeture, l’ajustement conjoint et les contrôles négatifs.
3. Si la question est de savoir si la « base DM est trop faible », aller directement à la section 9 et au tableau B1 / à la figure B1.
4. Pour une vérification technique, revenir au rapport technique P1 v1.1, au Tables & Figures Supplement et au full_fit_runpack.
Principaux points d’entrée d’archive |
Rapport technique P1 (niveau publication, Concept DOI) : 10.5281/zenodo.18526334 |
Paquet complet de reproduction P1 (Concept DOI) : 10.5281/zenodo.18526286 |
Base de connaissances structurée EFT (facultatif, Concept DOI) : 10.5281/zenodo.18853200 |
Note de licence : le rapport technique utilise CC BY-NC-ND 4.0 ; le paquet complet de reproduction utilise CC BY 4.0 (selon le rapport technique et les archives Zenodo). |
15 | Références et contexte externe
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.